

A friend of mine has a crazy amount of Reddit karma and gold, and yesterday he let me in on his secret. This person, who will remain unnamed for obvious reasons, created a Python script called Reddit Karma Crawler that finds rising posts before they get too popular.
Every good Reddit user knows that the key to getting massive comment karma is saying the right thing at the right time. Well, this script simply helps find that "right time," and my unnamed source says he uses it regularly to help him find his 500- to 800-point sweet spots.
The Reddit Karma Crawler Script
The concept behind the code is simple. It crawls through Reddit and collects posts from the past hour with high upvotes, few comments, and a place on the front five pages. Basically, it predicts which posts are about to get real busy.
Is this cheating the Reddit system? In my opinion, no. While this script will help find the sweet spots, it will not help anybody come up with something clever, witty, or informative to say.
Reddit is a community with its own nuances and style. Using this script and writing any old comment won't do anyone any good. The author of this script is a veteran user, and knows exactly what Reddit likes to hear. Ultimately, it's the words of the Redditor that wins karma, not a script.
Testing the Reddit Karma Crawler Script Out
To see just how this thing worked, I gave it a try myself and it worked pretty well, but it's a lengthy process for someone not used to working with Python scripts, so I will attempt to show you how it works.
Depending on which version of Python is running, either the Python 2.7 or the Python 3.4.1 script will be needed. The .py files are listed below.
Running the Reddit Karma Crawler
As already discussed, the Reddit Karma Crawler is a script written in Python, a widely-used programming language. In order to run this script, you will need three things:
- Selenium - a tool records and plays back user interactions with the browser automatically
- Mozilla Firefox - the browser that Selenium works with
- Software that can interpret Python and "print" the code's results, such as PyCharm
This will also work on either Mac or PC. I'm using a Mac for the detailed instructions below, but I've also included the alternative methods for Windows users.
Step 1: Download the Reddit Karma Crawler Script
Using the links above, download the appropriate Python script for whatever version Python you have. In this guide, I will be using the version for Python 2.7, because that is the syntax my IDE recognizes. If this is your first time running a script, I would suggest using version for 2.7.
Step 2: Install Selenium to Automate Your Browser
To run the Reddit Karma Crawler, we will need a suite of tools called Selenium to automate Firefox. Fortunately, Mac has a package manager called "easy_install" that we can call on to retrieve Selenium. To do this, you will need to open the Terminal app located in your Utilities folder.
After your "~ username$" (in my case, "~ nicholasmiller$"), type in the following code and hit Enter/Return.
- sudo easy_install selenium
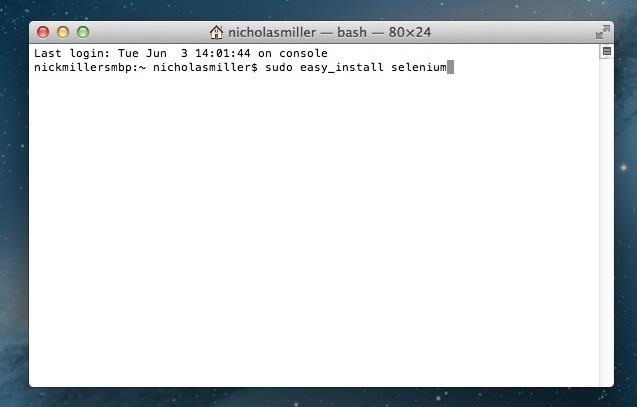
You will be asked to insert your admin password. It's important to note, however, that although you can't see your password as you write it, it is still there. I once spent 45 minutes browsing message boards trying to figure this out. The password is invisible.
After entering your password and clicking Enter/Return again, your Terminal will install Selenium.
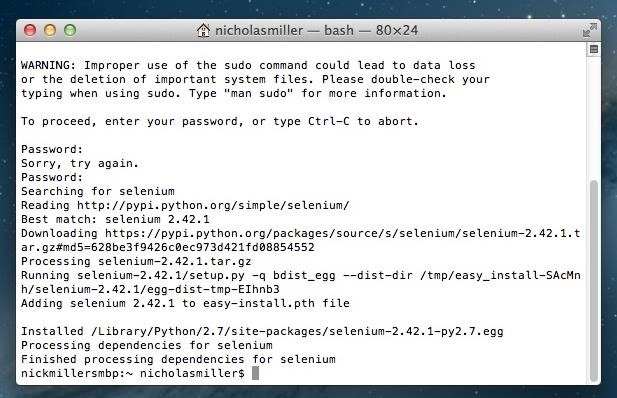
Installing Selenium for Windows
For Windows users, install Python 2.7.6 and download get.pip.py and run the following in a command prompt:
- python get.pip.py
This will trigger an automated process that will allow you to install Selenium through "pip." Then, to install it, use this command:
- C:\Python27\Scripts\pip.exe install selenium
Selenium should now be installed on Windows, and you should skip to Step #6 below, as Steps #3 through #5 do not apply to Windows, as you do not need IDE to run the script.
Step 3: Install an IDE on Your Mac
Now, Selenium is just a set of tools. In order to edit and run the code, you're going to need an integrated development environment (IDE) that recognizes Python (the language Reddit Karma Crawler is written in).
There are tons of free IDEs available for download, but for Python, I use a trusted free software called PyCharm by JetBrains. Install it if you'd like, as I will be using it in this example, but every IDE is very similar and this tutorial should help regardless of which IDE you download.
Step 4: Create a Project in PyCharm
Once PyCharm is installed, you'll need to select "Create New Project."
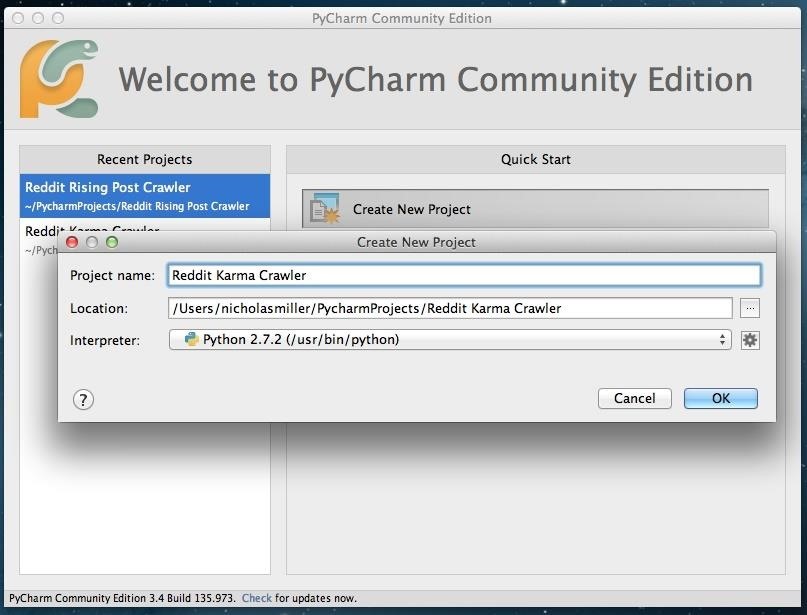
PyCharm will ask for a project name and file location. Chose what you'd like. The default file location will be a file created by PyCharm specifically for your projects. Keep Python 2.7.2 the interpreter and move on.
Step 5: Add the Reddit Karma Crawler File
When the new project opens, it will give you the option of dragging and dropping files in. The file you will be dropping in is the script you downloaded called either RedditKarmaCrawler27.py or RedditKarmaCrawler341.py, depending on which one you selected.
Drag and drop the file and voilà! There she is.
Step 6: Run Reddit Karma Crawler
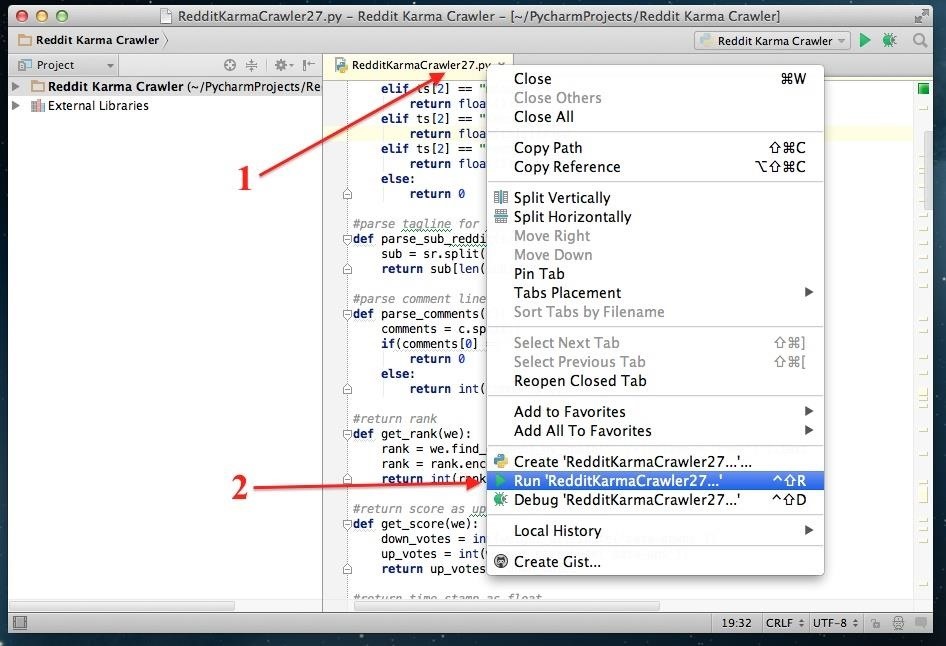
To put the code to work, first right-click the tab of the file and select "Run 'RedditKarmaCrawler…".
Running It from Windows
If you use Windows, you can run the script by using IDLE, which you can open up from your Python folder. Once IDLE is open, got to File -> Open, and select the Reddit Karma Crawler script you downloaded earlier. When the file opens, click Run and select Run Module.
Step 7: Locate Posts Before They're Too Hot
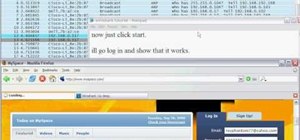
While the script is running, a new Firefox window will open and close Reddit several times. Let it do this—that's Selenium at work.
When it's finished, the script will "print" the results in the box at the bottom of the IDE. You will see links to Reddit posts along with their rank, points (upvotes), number of comments, hours they've been up, and sub.
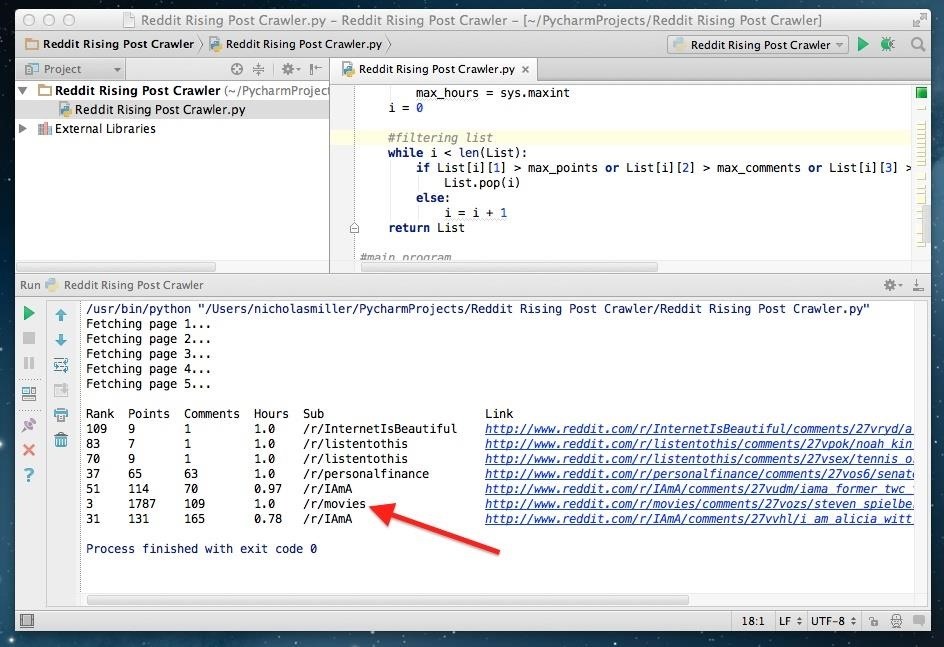
Look for links with a great disparity between upvotes and comments. In this example, a thread in /r/movies has 1,787 upvotes and only 109 comments. This would be a perfect post to comment on.
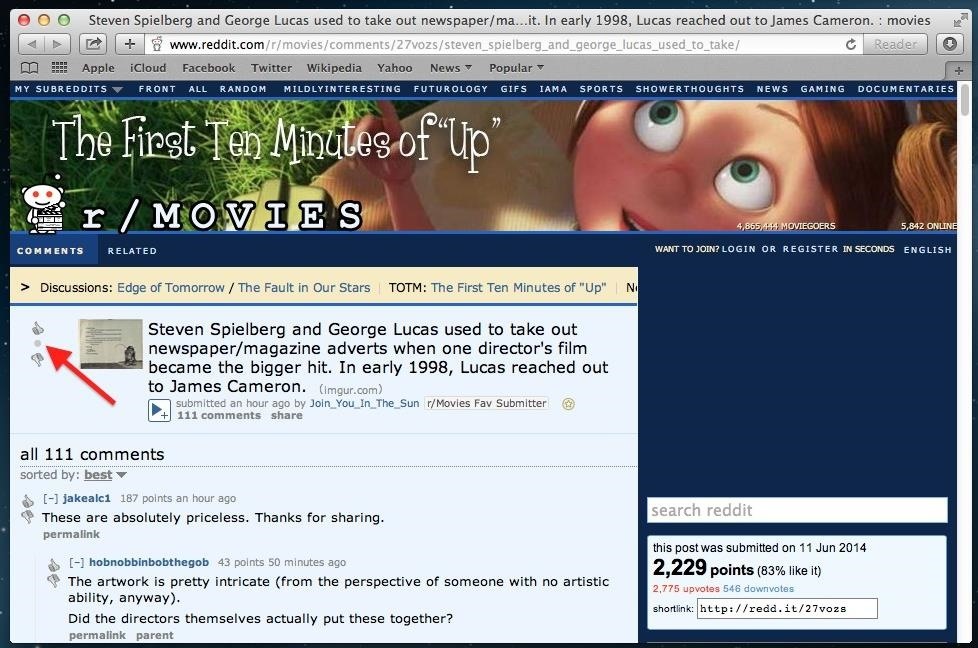
Another cool feature of the Reddit Karma Crawler is that it tells you when a posts upvotes before Reddit even makes them visible. Notice how this post in /r/movies has a bullet point instead of the number 1,787? You know its hot before anyone else.
Step 8: Modify the Script (Optional)
At the very bottom of the code you will see a set of variable you can change if you'd like to modify how the script works.
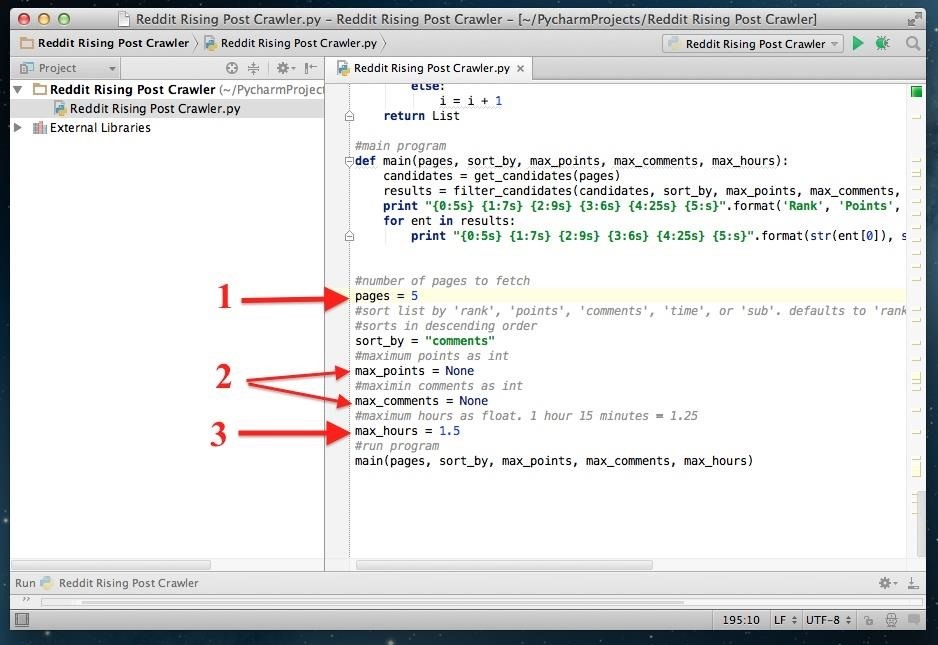
- Lets you modify the pages Reddit Karma Crawler crawls through. If you want more results, try changing it to 10.
- Lets you define max points and max comments. If you think 200 comments is too many to be noticed, go ahead and replace "None" with 200. Any posts with more than 200 comments will be ignored.
- Lets you define the max amount of hours the post has been on Reddit. Right now it is set to 1.5 hours, but if you think posts up to 3 hours old still have a chance of blowing up, go ahead and change 1.5 to 3.
Closing Thoughts
Reddit Karma Crawler is a small easy script with the potential to be a lot of fun, but prepare to suffer the wrath of angry Redditors if you get caught. There's nothing illegal going on here, you're simply automating a process you could do on your own if you had the time, but surely some Redditors will think of it a different way.
Just updated your iPhone? You'll find new emoji, enhanced security, podcast transcripts, Apple Cash virtual numbers, and other useful features. There are even new additions hidden within Safari. Find out what's new and changed on your iPhone with the iOS 17.4 update.













4 Comments
Cool Tut, Verified working as well.. Only problem is I like WHT not Reddit. ;-)
Followed all steps up until step 6. Terminal shows selenium successfully installed. Selenium folder found in library/python/2.7/site-files. When ever I run the RedditKarmaCrawler.py in PyCharm,
PyCharm: "/System/Library/Frameworks/Python.framework/Versions/2.5/bin/python2.5 /Users/santarini/Downloads/RedditKarmaCrawler27.py
Traceback (most recent call last):
File "/Users/santarini/Downloads/RedditKarmaCrawler27.py", line 1, in <module>
from selenium import webdriver
ImportError: No module named selenium"
What am I doing wrong? Or not doing right?
Between Step 6 and 7, when i run module, it opens firefox but then i get this error:
Traceback (most recent call last):
File "C:\Users\Philip\Desktop\RedditKarmaCrawler27.py", line 204, in <module>
main(pages, sortby, maxpoints, maxcomments, maxhours)
File "C:\Users\Philip\Desktop\RedditKarmaCrawler27.py", line 185, in main
candidates = getcandidates(pages)
File "C:\Users\Philip\Desktop\RedditKarmaCrawler27.py", line 107, in getcandidates
page = getpageinfo(driver)
File "C:\Users\Philip\Desktop\RedditKarmaCrawler27.py", line 89, in getpageinfo
score = getscore(divtagsi)
File "C:\Users\Philip\Desktop\RedditKarmaCrawler27.py", line 46, in getscore
downvotes = int(we.getattribute('data-downs'))
TypeError: int() argument must be a string or a number, not 'NoneType'
Can someone please help me fix this issue?
Awesome tutorial mahn. I'm not even on reddit but tell your friend I admire him and I got so much respect for him. And thanks for the detailed instructions
:)
Share Your Thoughts